当一台人形机器人突然做出了 C 罗标志性的「180 度空中旋转跳跃庆祝动作」,随后又稳稳完成了科比的后仰跳投 —— 这不是科幻电影的场景,而是卡内基梅隆大学与英伟达团队近期在仿人机器人领域的突破性成果。他们开发的ASAP 框架(Aligning Simulation and Real-world Physics),首次让机器人在真实环境中实现了媲美人类的敏捷全身动作,为机器人从实验室走向现实场景迈出了关键一步。

「科比」后仰跳投

「C罗」招牌庆祝动作
1

本篇论文主要讲了如何让仿人机器人更灵活地完成各种动作,比如跳跃、单腿平衡等。核心问题是模拟环境和真实物理世界之间的差异,导致机器人在模拟中练得很好,但到了现实中就不好使。现有的方法要么需要大量手动调参,要么让机器人动作保守,不够灵活。
01
核心方案:ASAP 框架
文中提出了一个叫 ASAP 的两阶段框架,分两步解决这个问题:
第一阶段:模拟训练
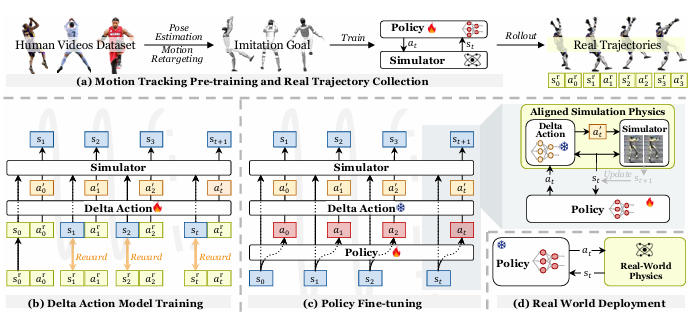
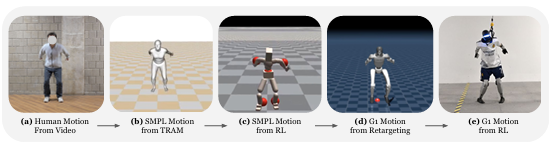
先从人类动作视频中提取动作(比如 C 罗的庆祝跳跃、科比的后仰跳投),用算法把这些动作 “翻译” 成机器人能做的姿势(这个过程叫动作重定向)。
在模拟环境中训练机器人模仿这些动作,让它学会基本的动作跟踪能力。比如,让机器人在模拟里练习怎么跳起来转 180 度。
第二阶段:真实世界校准
把模拟中训练好的机器人放到现实中测试,记录它的实际动作数据(比如关节位置、速度)。
发现模拟和现实的差异后,训练一个 “补偿模型”(叫 Delta 动作模型),专门计算模拟动作需要调整的部分。比如,如果模拟中机器人跳得比现实高,这个模型会自动减少腿部动作的强度。
用这个补偿模型调整模拟环境,让模拟更接近现实,然后再微调机器人的控制策略,让它适应真实物理特性。
02
关键成果
多种动作实现:在 Unitree G1 机器人上成功实现了多种高难度动作,比如 1.5 米前跳、单腿平衡、模仿 NBA 球星的庆祝动作等,这些动作以前很难在真实机器人上做到。
对比实验效果好:和传统方法(如系统辨识、域随机化)相比,ASAP 显著降低了动作跟踪误差。比如在从模拟到现实的迁移中,误差减少了 52.7%,动作更精准灵活。
数据驱动的补偿:通过真实数据训练补偿模型,不需要手动调整机器人的物理参数(如质量、摩擦力),节省了大量调参时间,还能适应复杂的现实差异。